
The SMCE Increases Speed to Science
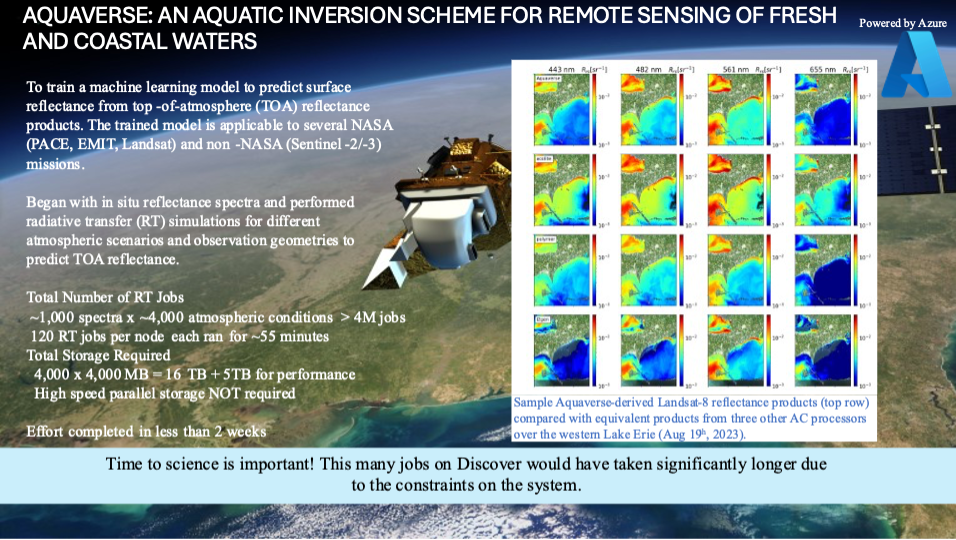
In May of 2023 Ashapure, Pahlevan, Wainwright, Smith, Saranathan, and Zhai presented the success of the Aquaverse approach of using machine learning to create a more accurate robust atmospheric correction method for estimating remote sensing reflectance for aquatic remote sensing. It was also identified that with the superior results that were achieved the approach could be expanded by enhancing their training dataset.
To start the effort to improve the Aquaverse capability, reliability, and robustness the training datasets would have to be able to be reflective of more diverse water types and reflectances. Towards this end the representative samples were more than quadrupled to nearly 2000 to ensure better representation of diverse water types and finer resolution angles and a greater number of atmospheric conditions were included The resulting more comprehensive dataset would then be comprised or nearly 4.5 million top-of-atmosphere (TOA) samples computed by Radiative Transfer Simulations (RTS).
These RTS runs were performed in the Microsoft Azure cloud using a 12,000 core quota to accommodate 100 concurrent operational nodes each with 120 cores at a spot price of $0.37/node/hour. The runs were deployed in 8 batches each with over 500K individual RTS runs, each running on 1-core. Most runs took a little less than 1 hour to complete. The completion of all 8 batches took about 2 weeks.
Akash Ashapure (GSFC, SSAI) and Ryan O’Shea (GSFC, SSAI), together with Hoot Thompson, and Dorian Crockrel, both on the SMCE, worked closely together and with Microsoft support team, Jerry Morey, Rob Murray, Mark Sullivan, and Patrick Egekenze, to enable very high efficiency of the code and hardware/cloud environment. The scaling up to 12K cores resulted in identified I/O issues. These were resolved by moving the file systems to Azure Services (Azure Files NFS) and right sizing this storage. In total the effort required 21TB of Azure Files NFS. One item that had to be changed in the code was the elimination of zipping files within the processing as this doubled the demand on the /shared directory, now moved to the more expensive but faster Azure Files NFS. The SLURM array capability was not working to capacity and MSFT support was able to identify the issue and correct it.
More than 4.4 million samples were successfully computed. The next step for Aquaverse is to now use these in the updating of the machine learning model and to assess the improvements achieved. This will be performed on Discover. Of the 21TB, 20TBs were transferred to Azure Blob storage. 8TB of that were the individual samples which were downloaded directly to Discover. The remaining 12TB, which contains raw h5 data and scripts was downloaded directly to MODAPS.
The processing of the machine learning model will now be performed on Discover. We hope to have results soon.